
This is an article from packetpushers.net. I found it very useful and informative.
1. Introduction
In this post we will be looking at large scale RR design by using a fictional ISP ACMEas a reference. As usual, I am assuming that the reader has familiarity with BGP and basic RR concepts.
2. Setting the Stage
ACME is a communications company providing communications and data services to residential, business, governmental and wholesale customers. It has around 200 POPs and 50 core locations. Each Core location consists of 2 Core Routers (CR) and each POP (connected to a core location) consists of 6 Provider Edge (PE) bringing the total number of routers to 1300 (100+1200). ACME runs a flat single Level IS-IS (Level2) domain for the IGP. ACME serves following services:
- Layer 3 VPN
- Layer 2 VPN
- Internet
Out of 6 PE’s in each POP, 2 PE’s are dedicated to VPN (L3VPN, L2VPN etc.) functionality and 4 PE’s are for Internet Services. ACME runs a BGP free core and PE routers are running BGP for providing various services like L3VPN, L2VPN or Internet. ACME guidelines for Routing is to exit the traffic as soon as possible aka Hot Potato Routing. ACME had already implemented MPLS-TE to achieve FRR (and maximize link utilization) in the Core and IP FRR in the POP’s. They would also like to achieve Fast-Recovery and multi-pathing for BGP learned prefixes.
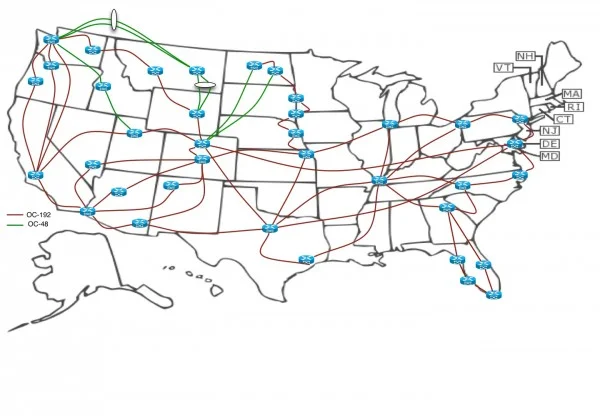
Fig.1 ACME BackBone
3.Why BGP RR?
As you can see that the number of PE routers in ACME network is around 1200.Running 1200 routers in an iBGP full mesh leads to a total of 719,400 (N* (N-1) / 2) iBGP sessions. This large number of iBGP sessions create problems not only from an iBGP session management perspective, but also from an operational perspective as the addition or removal of a router needs an operator to touch all the PE routers in the mesh which is a very costly operation. Additionally, with this many numbers the memory needed to storeAdj-rib-in will be huge.
So they looked into BGP Confederation and BGP RR’s as possible ways to solve this problem and chose BGP RR over confederation for simplicity reasons.
4. RR per service
So the next question is should ACME use BGP RR cluster per service or a single RR cluster serving multiple services. Having a single RR cluster serving multiple services has the obvious benefit of less management overhead but also less flexible. ACME preferred the flexibility and decided to use separate RR cluster’s for VPN services (L2VPN, L3VPN) and separate RR clusters for Internet services. This will allow each cluster to grow accordingly to the popularity of the service.
5. Out of Band RR
Since ACME aren’texposed to forwarding loops in their network as they use label forwarding (LDP in POP and RSVP in Core) for Internet and VPN traffic, this opened up the possibility of putting RR’s out of band. This further opens up the room for innovation like now they can explore options of putting RR function on VM’s (nFV).
6. Redundant RR’s
ACME has decided to deploy RR’s in pairs for each service for redundancy purposes. Now the question is whether one puts them in the same cluster (by defining the cluster-id) or use different cluster-id’s. So lets take a look at the scenarios briefly.
Different Cluster-ID’s with RR’s peering with each other
In the below case when A receives a prefix “P” from an eBGP neighbor (D), it advertises to both Route Reflectors (RR1 and RR2). RR1 creates a new update with cluster-list attribute set to its own cluster-id i.e. 1.1.1.1 and originator-id to A. Then RR1 advertises this to B, C and RR2.
RR2 receives the update from RR1 and don’t see his cluster-id in the list. So it accepts the update and prepends its own cluster-id to the cluster list, which means the cluster-list is now (2.2.2.2,1.1.1.1).RR2 also receives the update from A, and set the cluster-list attribute to its own cluster-id i.e. 2.2.2.2 and originator-id to A. RR2 runs the best path algorithm and prefers the Route from A because of shorter cluster-list and advertises the update to B, C and RR1.
RR1 receives the update from RR2 and does similar to what RR2 did i.e. adds its own cluster-id (1.1.1.1) to RR2 update which makes the cluster-list looks like (1.1.1.1,2.2.2.2) and runs the best-path algorithm and prefers the Route from A over RR2 due to shorter cluster-list.
RR clients B and C will receive two copies of the update from Route Reflectors RR1 and RR2. RR’s (RR1 and RR2) store two copies of the update, one directly from the client and other from each other.

Fig.2
Same Cluster-ID with RR’s peering with each other
In this situation when A receives a prefix “P” from an eBGp neighbor (D), it advertises to both RR’s (RR1 and RR2). RR1 creates a new update with cluster-list attribute set to its own cluster-id i.e. 1.1.1.1 and originator-id to A. RR1 advertises this to B, C and RR2.
RR2 gets the update from RR1 and sees its cluster-id and discards the update. RR2 also receives the update from A, and set the cluster-list attribute to its own cluster-id i.e. 1.1.1.1 and originator-id to A. RR2 sends the update to B and C.
RR clients B and C will receive two copies of the update from Route-Reflectors RR1 and RR2. RR’s store only one copy of the update so less overhead on the RR’s memory

Fig.3
So as you noticed that if RR’s are peering with each other and have different cluster-id’s then they have to store more than just one copy of the route hence an increase in the memory requirement on RR’s. What if we don’t peer them with each other?
The problem we will run into is with a double failure situation, for instance in below fig. 4, If A looses connectivity to RR1 and C looses connectivity to RR2 then C will not get reachability information for the prefix “P”.

Fig.4
If you want to get a better understanding about RR cluster coneptthen take a look at what Orhan has written about just this particular topic http://orhanergun.net/2015/02/bgp-route-reflector-clusters/.
7. Benefits of RR
The ACME team analyzed the benefits of RR found possible benefits of introducing RR in the network
- Reduced number of iBGP Sessions and Adj-RIB-in size.
- Reduced Opex
- Reduced number of BGP updates (This one may need some explanation)
- With a significant reduction in the number of its iBGP neighbors, a client router naturally receives a significantly reduced number of updates. A route reflector RR receives routing updates from all its neighbors, but since BGP only propagates the best path to each destination, RR further propagates only those updates that change its best path selections. Assuming an AS has NBGP routers, if it uses full-mesh BGP connections, every iBGP speaker processes roughly the same amount of updates coming from the (N − 1) sessions, putting a high processing demand on all the routers. If an AS adopts a simple route reflection topology with MRRs, only the RRs have (M − 1) + CiBGP sessions ((M-1) for full-mesh connection among RRs and C connections to client routers); the rest client routers only need to connect to a few RRs. This differentiated processing load and memory requirements support a heterogeneous router environment where routers (probably Virtual) with more compute power (memory and CPU) can be used as reflectors (RR’s running on a VM are a perfect fit (nFV)) without increasing the memory stress on the client routers.
8. Challenges with RR
So we looked at the good news and now time for some bad news. ACME noticed three big issues with the introduction of the RR’s in the network
1) Increased Routing Convergence time
In the case of full-mesh iBGP an update travels only one iBGP hop to reach all other iBGP routers. In the case of RR’s a BGP update has to travel through one or moreRR before it reaches the final iBGP router. Introducing a RR in the topology not only increases the propagation delay (because of additional hop’s) it also increases the processing delay as the RR’s runs the best path algorithm on the routes received before reflecting them to RR clients.
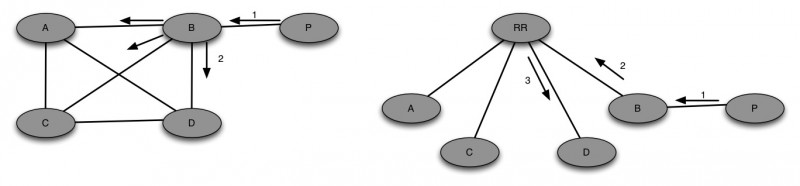
Fig.5
This increase in a processing delay due to RR’s couldbe made irrelevant if somehow the clients get post convergence path visibility beforehand.
2) Sub-Optimal Routing
A RR selects the best path based on the local routing information available to him and reflects them to the clients. This is a major drawback which can result into sub-optimal routing and a major deterrent in achieving Hot Potato Routing. Examples below show how sub-optimal routing is happening for Intra and Inter POPs.
Inter POP:
For instance, in the below Fig.6 (A); a Prefix “P” is learned by the ISP from both East and West cost POP’s. Assuming the RR’s are sitting somewhere closer to West Coast Router (IGP Cost for West is 10 vs 20 for East Coast), RR chooses POP A as the best path and reflects to its east and West coast clients. This is fine for the West coast POP B which will use POP A as the exit point for prefix “P” which is the closest exit point, but for POP D its sub-optimal as from POP D’s point of view the closest exit point is through POP C not POP A and traffic from the east coast will travel all the way.

Fig.6 (A)( Inter-POP)
Intra POP:
PE B traffic for prefix “P” is going to follow East POP as RR’s is only reflecting the prefix learned from East POP even though from PE B perspective optimal route would have been to follow PE A.
One could bring up the point that why not enable nerd knob like “bgp bestpath igp-metric ignore”(couldn’t find similar on Juniper) on the RR’s but that actually doesn’t solve the problem and in fact, it could make it worse as the path selection moves to more non-deterministic factors like router-id, oldest BGP path etc.

Fig.6 (B)(Intra-POP)
This challenge makes RR placement very important. If the RR is placed close to the clients, then most likely its best path will be also the Clients best path.
3) Reduced Path Diversity
One of the very basic principle for achieving fast convergence is to pre-calculate the backup path. You might have noticed this principle with MPLS-TE FRR and IP FRR. Similarly fast convergence for BGP prefixes (BGP PIC Edge) can be achieved by pre-calculating next best path for the prefix “P”. This is pretty easy to achieve in a full-mesh iBGP configuration as an iBGP neighbor has visibility to all the paths from its iBGP neighbors. The problem we face with introducing RR’s is that an iBGP neighbor looses visibility to all the possible paths for prefix “P” as RR only sends the best path to the RR clients.
The other impact is around multi-pathing. If there are 5 equal paths for a prefix “P” then ideally one would prefer to use all the five paths equally. Again, as RR’s just sends the best path, one looses capability of load balancing for BGP prefixes “P”.
4) Forwarding Loops
Though this could be a problem with the introduction of RR’s but is only limited to networks doing IP forwarding. Networks like ACME who rely on label forwarding aren’t exposed to forwarding loops.
5) Routing Oscillations
A Network with RR’s can be exposed to routing oscillations caused due to MED (known as MED oscillations).Please take a look at following https://tools.ietf.org/html/rfc3345 if you aren’t aware about it and this has been covered at length in many places. The primary reason for oscillations is at any given moment lack of visibility of all paths for a prefix “P” during the best path selection process as RR’s are hiding the paths. MED oscillations can be remedied by following certain deployment considerations or enabling BGP Add-Path (Which we will look later). ACME follows following deployment practices to reduce the chance of MED oscillations:
- Uses MED only when needed. By default MED attribute is reset to zero for any path received from an external Peer. They are also looking at implementing higher local pref or communities based on the MED received from external neighbors.
- Intra cluster distance (i.e. Distance between RR and its clients) is always less than Inter-cluster distance (i.e. distance between RR’s clusters)
- Routers have “deterministic-med” and “always compare-med” knobs turned on to avoid the inconsistent route selection.